
Red-black trees (part 2)
published: Mon, 3-Mar-2008 | updated: Sat, 3-Nov-2018
Now that I have the technology available to draw trees quickly and accurately (and you have seen the algorithm and its implementation at first hand), it's time to go back to the main subject: red-black trees. Except that I have some more foundation to lay first. So in this episode we'll look at binary search trees, and how to insert new nodes into them. After all, visually, a red-block tree is a binary search tree with colorful nodes.
Last time we saw the definition of a binary tree. It's a recursive definition, and to put it in a slightly different way: a binary tree is either a single node or is a node with one or two binary trees as children, known as the left and right child.
In a binary search tree we impose a little more structure to this bald definition by adding an ordering relation. By "ordering relation" I mean that, given two nodes, I can say that one is smaller than the other. (We'll ignore equality for the moment.) Of course I'm using shorthand here: by saying that one node is smaller than another, I'm really saying that each node contains a "key" (a value of some type), and it is those key values that get compared.
Let us imagine that our nodes are containers for single character keys (they're are easier to draw inside a circle representing a node). We can look at two distinct nodes and say that the character key in this node is smaller than the character key in that one. Or if the keys were integers, that the integer in this node is smaller than the integer in that node. Mind you it gets a little tedious to continue saying "the key in this node is smaller than the key in that one", so we'll continue to take the shortcut and say "this node is smaller than that one", understanding that the ordering relation is on the keys not on the nodes themselves.
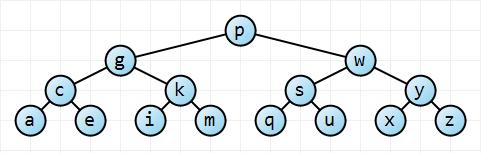
Having been utterly pedantic on that point, we can now give the definition of a binary search tree. A binary search tree is a binary tree where, for every node, the left subtree, if present, contains nodes that are all smaller than that node, and the right subtree, if present, contains nodes that are greater than that node. In fact, if you were to list all the nodes using an in-order traversal, you'd find that all the nodes were... in order. (BTW, a quick note to Dustin is in order here: check out the gradient fill, dude.)
To find a given key in a binary search tree, we can use a recursive or iterative process, much as we do with binary search. Although many search routines are written as iterations, as will mine, it'd be instructive for you to try and write it as a recursive method. To find s in the tree shown, we'd start at the root (it's the only place we know of, anyway). Does the key in the root equal s? No, so in which child subtree will it be found? Since s is greater than p, it'll be in the right subtree. Move down to the right child, and repeat the same process. Is it equal? No? Then in which subtree will it be found? Every time we reach a node and apply our comparison check, we eliminate "half" the nodes remaining in the tree. I put "half" in quotes because it depends on the balance of the tree, which we'll get to in a moment.
If we ever get to the point where we can't move down the tree any further and haven't yet found the search key, then we can say that the value we seek is not there.
The Find operation for a binary search tree is very efficient, provided that the tree is balanced. By "balanced" I mean that the tree looks bushy — every internal node generally has two children — and that there are no long "twigs" where there's a chain of nodes with only one child, one after the other. In other words, every path from root to leaf (those are the nodes at the bottom) is roughly the same length. I've cheated in my image above: I created a perfectly balanced tree. Not only that, but it is complete — the last level has all its possible nodes.
Using this tree, we can make some calculations. If there were only one level in the tree, we'd find our key (or not, as the case may be) with only one comparison. If there were two levels, there would be three nodes, but we'd only need to make at most two comparisons (I'm assuming that a comparison returns one of three values, less than, equal to, or greater than, rather than say just is greater than or not, requiring another comparison for equality). For three levels, there are at most seven nodes, but only three comparisons are required. For four levels, 15 nodes and four comparisons. Now — watch carefully here — for n levels, there would be at most 2n-1 nodes, and we'd only need a maximum of n comparisons in order to find a key or determine if it wasn't there at all.
In general, with some hand-waving, we can say that for a reasonably balanced tree (rather than the perfectly balanced ones I just used in our thought experiment), for n nodes we'd need at most log(n) comparisons to determine whether a key was present or not. And because comparisons tend to take the most amount of time when searching (following a link is simple stuff indeed), we say that the Find operation in a reasonably balanced binary search tree is O(log(n)). Or, to put it another way, if you square the number of items in a binary search tree (say from 100 to 10,000), and maintain its balance, you only double the time it takes to find a value (or not).
Compare that result with a linked list, say. Since the number of comparisons needed to determine that a value is not present in a linked list is equal to the number of items in the linked list (we assume that the items are not ordered), merely doubling the number of items (say from 100 to 200) doubles the time taken.
Let's look at inserting nodes into a binary search tree, since repeated applications of this operation is the means by which we get a binary search tree to search in the first place.

The easy case: if we're inserting a node into an empty tree, the node becomes the root of the tree. Here the p key is the first node in the tree.
Otherwise, we search for the new key to be inserted. If we find the key already in the binary search tree, we throw an exception: equal keys are not allowed.
(Aside: what to do about equal keys in a binary search tree is a thorny question. Over the years of using keyed containers like the binary search tree, I've never really hit a scenario where I absolutely, positively, definitely had to have two or more items with the same key in the container. I've always had more than enough information to differentiate the items, maybe with the help of other fields of the item. At a last resort, I can see using bucketing as a solution: the keyed container just contains a bucket of items for each key. Hence, in this series, I'm going to insist on no key duplicates.)
Eventually we reach a leaf node without finding the key. The new item (key and value pair) will be a child of this node, which side depending on whether the key we're inserting is greater than or less than this node. And that's it.
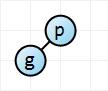
Adding the g key. Starting at the root we see that g is less than p, and so we add it as the left child of p since it hasn't one yet.
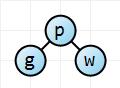
Adding the w key. Starting at the root we see that w is greater than p, and so we add it as the right child of p since it hasn't one yet.
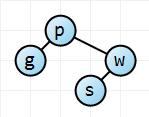
Adding the s key. Starting at the root we see that s is greater than p, and so we move down to the w node. s is less than w, so we add it as the left child of w since it hasn't one yet.
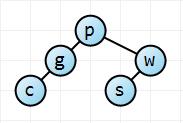
Adding the c key. Starting at the root we see that c is less than p, and so we move down to the g node. c is less than g, so we add it as the left child of g since it hasn't one yet.
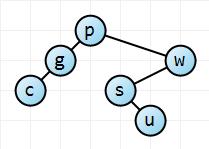
Adding the u key. Starting at the root we see that u is greater than p, and so we move down to the w node. u is less than w, so we move down to the s node. Finally u is greater than s, so we add it as the right child of s.
And so on, so forth (the code for this article shows adding nodes one by one, until the complete, balanced tree above is created).
Before we write the code, we need to address the question of how to test it. After all, it's a real cop-out if I just say: print off the tree after each insertion and ascertain visually that the binary search tree is valid. Maybe elsewhere authors can get away with that, but not here.
I can see two possible verifications for our tests: first: can we find the key we just inserted? Second, looking at every node in the tree, is the left child, if present, smaller than this node, and the right child, greater? (This test could be implemented using a pre-order traversal.) A third possibility — the one I'll use — is to check that an in-order traversal lists the keys in ascending order (this is equivalent to the second option, but miles easier to implement).
To thoroughly test it I'll just add a couple of thousand random numbers as keys to a new tree. For each one added, I'll check the structure to make sure we're not creating an invalid tree.
As for the actual code, it's a great example of removing code duplication. I certainly didn't originally write it like this, but it involved a set of refactorings using Refactor! Pro, trying to remove the duplication. Consider this: everything we do with a binary search tree involves a search for a key. Want to see if a key is there? Search for it. Want to get the value for a key? Search for it. Want to insert a new key and value? Search for the key, fail to find it and then add a new node where you stopped searching.
First up: the node class for a binary search tree:
C#: public class BsTreeNode<K, V> : SimpleNode where K : IComparable<K> { public BsTreeNode(K key, V value) { this.key = key; this.value = value; } public IBinaryNode Advance(K key) { int compareResult = key.CompareTo(Key); if (compareResult == 0) return this; if (compareResult < 0) return Left; return Right; } private K key; public K Key { get { return key; } set { key = value; } } private V value; public V Value { get { return value; } set { this.value = value; } } }
VB: Public Class BSTreeNode(Of K As IComparable(Of K), V) Inherits SimpleNode Private _key As K Public Property Key() As K Get Return _key End Get Set(ByVal Value As K) _key = Value End Set End Property Private _value As V Public Property Value() As V Get Return _value End Get Set(ByVal Value As V) _value = Value End Set End Property Public Sub New(ByVal key As K, ByVal value As V) _key = key _value = value End Sub Public Function Advance(ByVal key As K) As BSTreeNode(Of K, V) Dim compareResult As Integer = key.CompareTo(Me.Key) If compareResult = 0 Then Return Me If compareResult < 0 Then Return Left Return Right End Function End Class
As you can see it's generic and is implemented for a key of type K
(which obviously must be IComparable) and a value of type V. There's a
peculiar method called Advance() though. It's called on a node, takes
a key, and returns either the node itself if the node has that key, or
the left or right child of the node depending on where the key should
be found if it is there (so if the key is less than the node, the left
child is returned, if not, the right child). A nice little utility
routine that we're about to use in our search methods.
I then wrote a simple method of the BinarySearchTree class find the
node for a key. It uses this utility method from the node class.
C#: public class BinarySearchTree<K,V> where K : IComparable<K> { private BsTreeNode<K,V> root; public BsTreeNode<K,V> Root { get { return root; } set { root = value; } } private BsTreeNode<K, V> GetNode(K key) { BsTreeNode<K, V> walker = root; while (walker != null) { BsTreeNode<K, V> nextNode = walker.Advance(key) as BsTreeNode<K, V>; if (nextNode == walker) { return nextNode; } walker = nextNode; } return null; } }
VB: Public Class BinarySearchTree(Of K As IComparable(Of K), V) Private _root As BSTreeNode(Of K, V) Public Property Root() As BSTreeNode(Of K, V) Get Return _root End Get Set(ByVal Value As BSTreeNode(Of K, V)) _root = Value End Set End Property Public Function GetNode(ByVal key As K) As BSTreeNode(Of K, V) Dim walker As BSTreeNode(Of K, V) = _root While walker IsNot Nothing Dim nextNode As BSTreeNode(Of K, V) = _ DirectCast(walker.Advance(key), BSTreeNode(Of K, V)) If Object.ReferenceEquals(nextNode, walker) Then Return nextNode End If walker = nextNode End While Return Nothing End Function End Class
As you can see, it starts at the root and continues advancing until
either the correct node is found or we hit a null reference. Having
written this new utility method, writing a Contains() method is
simplicity itself.
C#:
public bool Contains(K key) {
return GetNode(key) != null;
}
VB:
Public Function Contains(ByVal key As K) As Boolean
Return GetNode(key) IsNot Nothing
End Function
Ditto, in fact, for the TryGetValue() method, which, when given a key,
either returns true, the key was found, and the value for that key, or
false and the default value for the V type.
C#:
public bool TryGetValue(K key, out V value) {
BsTreeNode<K, V> node = GetNode(key);
if (node == null) {
value = default(V);
return false;
}
value = node.Value;
return true;
}
VB:
Public Function TryGetValue(ByVal key As K, ByRef value As V) As Boolean
Dim node As BSTreeNode(Of K, V) = GetNode(key)
If node IsNot Nothing Then
value = Nothing
Return False
End If
value = node.Value
Return True
End Function
Next up is the Insert() method. The wrinkle to appreciate here is that
as we move down the tree, following links, we have to maintain a
reference to the parent of the current node. That way, when we finally
hit the null reference at the bottom of the tree, we have a node to
which we can attach the new node, either as the left child or the
right one.
C#:
public void Insert(K key, V value) {
BsTreeNode<K, V> parent = null;
BsTreeNode<K, V> walker = root;
while (walker != null) {
BsTreeNode<K, V> nextNode = walker.Advance(key) as BsTreeNode<K, V>;
if (nextNode == walker)
throw new Exception("Binary Search Tree: inserting duplicate key");
parent = walker;
walker = nextNode;
}
walker = new BsTreeNode<K, V>(key, value);
if (parent == null)
root = walker;
else if (key.CompareTo(parent.Key) < 0)
parent.Left = walker;
else
parent.Right = walker;
}
VB:
Public Sub Insert(ByVal key As K, ByVal value As V)
Dim parent As BSTreeNode(Of K, V) = Nothing
Dim walker As BSTreeNode(Of K, V) = _root
While walker IsNot Nothing
Dim nextNode As BSTreeNode(Of K, V) = _
DirectCast(walker.Advance(key), BSTreeNode(Of K, V))
If Object.ReferenceEquals(nextNode, walker) Then
Throw New Exception("Binary Search Tree: inserting duplicate key")
End If
parent = walker
walker = nextNode
End While
walker = New BSTreeNode(Of K, V)(key, value)
If parent Is Nothing Then
_root = walker
ElseIf key.CompareTo(parent.Key) < 0 Then
parent.Left = walker
Else
parent.Right = walker
End If
End Sub
This actually is the most complex method of the lot with a Cyclomatic Complexity of 5, right under my red flag.
Now with all that code written, we can write a quick indexer for the binary search tree class, just like the real CLR.
C#:
public V this[K key] {
get {
BsTreeNode<K,V> node = GetNode(key);
if (node == null)
throw new Exception("Binary Search Tree: Key not found using indexer");
return node.Value;
}
set
{
BsTreeNode<K,V> node = GetNode(key);
if (node == null)
Insert(key, value);
else
node.Value = value;
}
}
VB:
Default Public Property ValueByKey(ByVal key As K) As V
Get
Dim node As BSTreeNode(Of K, V) = GetNode(key)
If node Is Nothing Then
Throw New Exception("Binary Search Tree: Key not found using indexer")
End If
Return node.Value
End Get
Set(ByVal value As V)
Dim node As BSTreeNode(Of K, V) = GetNode(key)
If node Is Nothing Then
Insert(key, value)
Else
node.Value = value
End If
End Set
End Property
I won't show the test code here, but suffice it to say, the code above works perfectly.
Next time we have a bit more work to do with the basic binary search tree (mostly talking about how balanced a tree is), and then we'll be ready to discuss a red-black tree.
C# Source code. VB Source code. Note that this is a work in progress. These links merely point to the state of the code after part 2. There is a lot more to come.
[This is part 2 of a series of posts on red-black trees. Part 1. Part 3. Part 4. Part 5. Enjoy.]